Effective Graphviz
I’m a big fan of Graphviz. It’s an amazing tool to quickly generate all kinds of graph diagrams. See this simple example.
l1 [label="I get up in the evenin'"];
l2 [label="And I ain't got nothin' to say"];
l3 [label="I come home in the mornin'"];
l4 [label="I go to bed feelin' the same way"];
l1 -> l2 -> l3 -> l4;
It’s is a declarative language. Which is both good and bad. The good parts mean that you focus on content. Just express your model in declarative form and the tool - in this case, the dot tool - will convert it from text into a formatted png file. It worries about how to organize the graph. That is really magical and works well in many cases.
Except when it doesn’t.
The bad part of a declarative language is that you don’t have any escape mechanisms. No if clauses to special case those occasions when your graph ends up looking less than desirable. But there is a declarative way to affect layout and we’ll see them through examples.
Birds of a feather, flock together
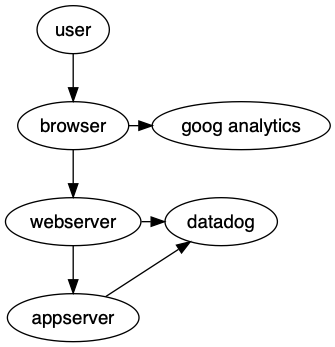
Let’s take a look at another example.
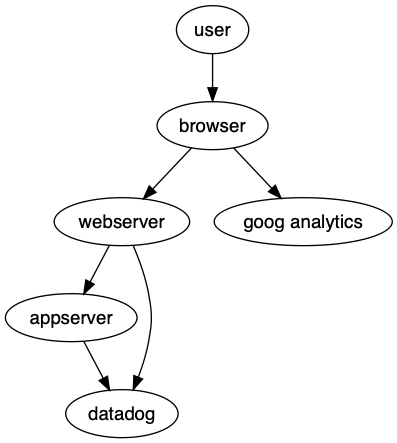
Figure 2’s layout is not what we want. The edges are correct; these are the dataflows we declared. But the node placement seems to suggest that datadog sits below our web and app servers. It seems to imply that we have control over it when we really don’t. Also google analytics has been put on the same level as our webserver. Are they really peers?
To fix this, we can use rank to declare which nodes are similar to each other. In our case here, we can say that the browser and google analytics are related to each other – rank wise. We can also make the webserver and datadog peers so it no longer appears we own datadog.
{ rank = same; browser ga }
{ rank = same; webserver datadog }
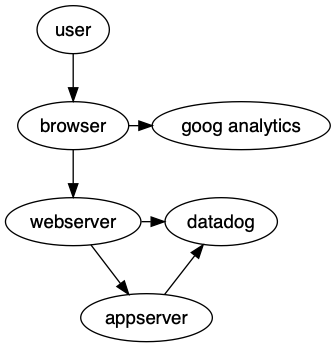
You might notice a trend with how layout is done. Each time you define an edge, the receiving node will end up on a lower level than the source node. That is, unless you tell the layout engine that the nodes should have the same rank.
Laying pipe
What if we wanted to create a horizontal graph, say for a pipeline process. How would we do that? Well, we could use the rank trick we just learned to make all the nodes of the pipeline be the same rank. But if all we’re rendering is the pipeline, then we’re going to try something else.
Let’s take a look at this pipeline example. Our first pass gives us something workable but not what we might want to see.
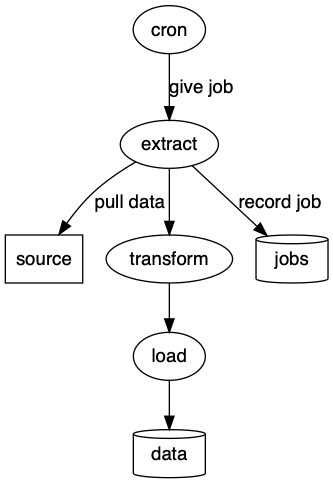
How can we improve this? We’d like the overall process to be horizontal. We could try changing the rank direction of the whole graph.
Normally graphs run top to bottom (TB), but we can change them to other directions like left to right (LR), bottom to top (BT) or right to left (RL).
rankdir = LR;
In addition to changing the graph to run left to right, we could apply our ranking trick we learned earlier.
{rank = same; src extr job}
{rank = same; load data}
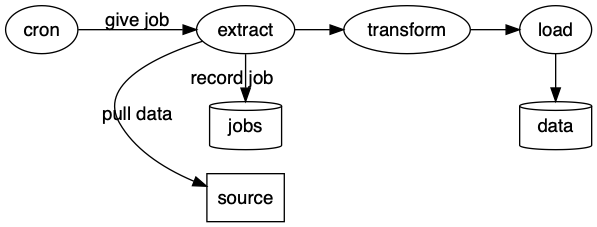
This is a big improvement over our previous diagram. It’s pretty good. But I don’t like that source is sitting below the jobs node. I want to show that source is from an external system so I really want it above the extract node. To figure out how to solve this we’ll take a quick sidetrack into how edges affect layout.
After you
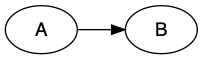
If we define an edge from a node A to a node B, then in the layout (in this case a left-to-right layout), the A node comes before the B node.
A -> B;
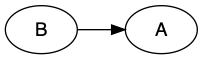
But what if we want the B node to come before the A node? Well we could try flipping the relationship around.
B -> A;
That places the B where we want relative to the A but now the arrow is pointing the wrong way. We can fix that by just changing the arrow on the edge by setting attributes.
B -> A [dir = back];
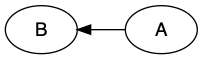
And there we have it. The B appears before the A and the arrow is pointing in the correct direction. There is an important lesson here about graphviz. Edge definitions tell graphviz how to lay out nodes. The attributes on the edges convey to the user the semantic meaning of the edge. Graphviz only cares about layout – it doesn’t understand semantics of rendered arrow direction.
Criss cross
Back to our problem in figure 3-1, we can now apply this trick to move the source node to the right place.
src -> extr [label = "pull data", dir = back];
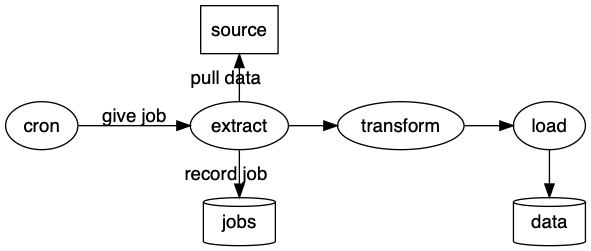
And there we have it, our data pipeline. cron gives jobs to extract. extract records job data in jobs. extract pulls data to source. What what?
Mmm… that’s a bit tough to read. We want to say that extract makes a request for data from source. extract initiates the event and source sends data back.
You could define two edges between source and extract to model this request/reply behavior, but I haven’t found a way to order the edges. That means it sometimes looks like extract generated the event and other times it looks like source was the initiator.
My solution is to use a bidirectional arrow to signify request/reply and then put the label on the node receiving the event.
So I now read this as extract pulls data from source.
src -> extr [taillabel = "pull data", dir = both];
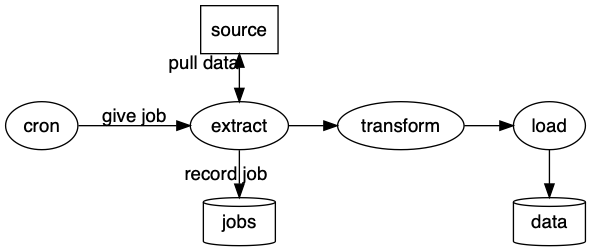
Sidenote: Graphviz uses the terms head and tail to describe edge definitions. From their perspective the tail points to the head.
tail -> head;
One more thing
Looking back at Figure 2-1, we see that our app server sits in the middle between our systems and third party ones. Ideally we’d want it right below the webserver. How could we do that?
One way to think about this is what would we expect if there was no edge between appserver and datadog? Where would the appserver node be rendered?
We’d expect appserver to sit below webserver, right?
So what we want is to have an edge between those two nodes but we want Graphviz to ignore it in terms of layout. Lucky for us, there’s an attribute for this very purpose. It says ignore this edge for constraint calculations (layout).
appserver -> datadog [constraint = false];
Summary
So what did we learn?
Graphviz refers to an edge as a relation from tail to head.
tail -> head;Edge declarations between two nodes are layout constraints. The tail node will always come before the head node.
tail -> head;means tail node will always render before head node.The overall graph has a layout direction defined by
rankdirwhich defaults toTB(top to bottom). We can change it toBT,LRorRLto suite our needs.We can make a tail and head node render on the same ‘level’ if we give them the same
rank.{ rank = same; tail head }The
dirattribute on an edge declaration has no impact to layout – it’s only a visual cue to the user of how to interpret the connection between the nodes.tail -> head [dir = back];We can tell the layout engine to ignore some edges.
tail -> head [constraint = false];
Resources
Source code for figures: